Today, I applied my plan from yesterday.
To format the items in each cell, I learned about
list comprehensions,
an elegant and efficient way to create lists in Python.
For each cell,
I used a list comprehension
to create a list of all the diagnoses within the year interval.
Then, I merged the elements together with join().
During my research on how to combine the diagnoses together,
I came across
a very informative write-up
that warned against iteration. The author writes,
“[i]teration in Pandas is an anti-pattern
and is something you should only do when you have exhausted every other option”.
That shocked me!
I remember that I and fellow Energize Andover members had often used
iterrows() in our code.
Reading on, I learned that iterating through DataFrames is much slower than
the other options that Pandas provides for multi-element operations.
One option is using vectorized functions.
In contrast to iteration, where single elements are processed repeatedly,
vectorization is where multiple elements are processed
with a single operation simultaneously.
This leads to great improvements in performance for large datasets.
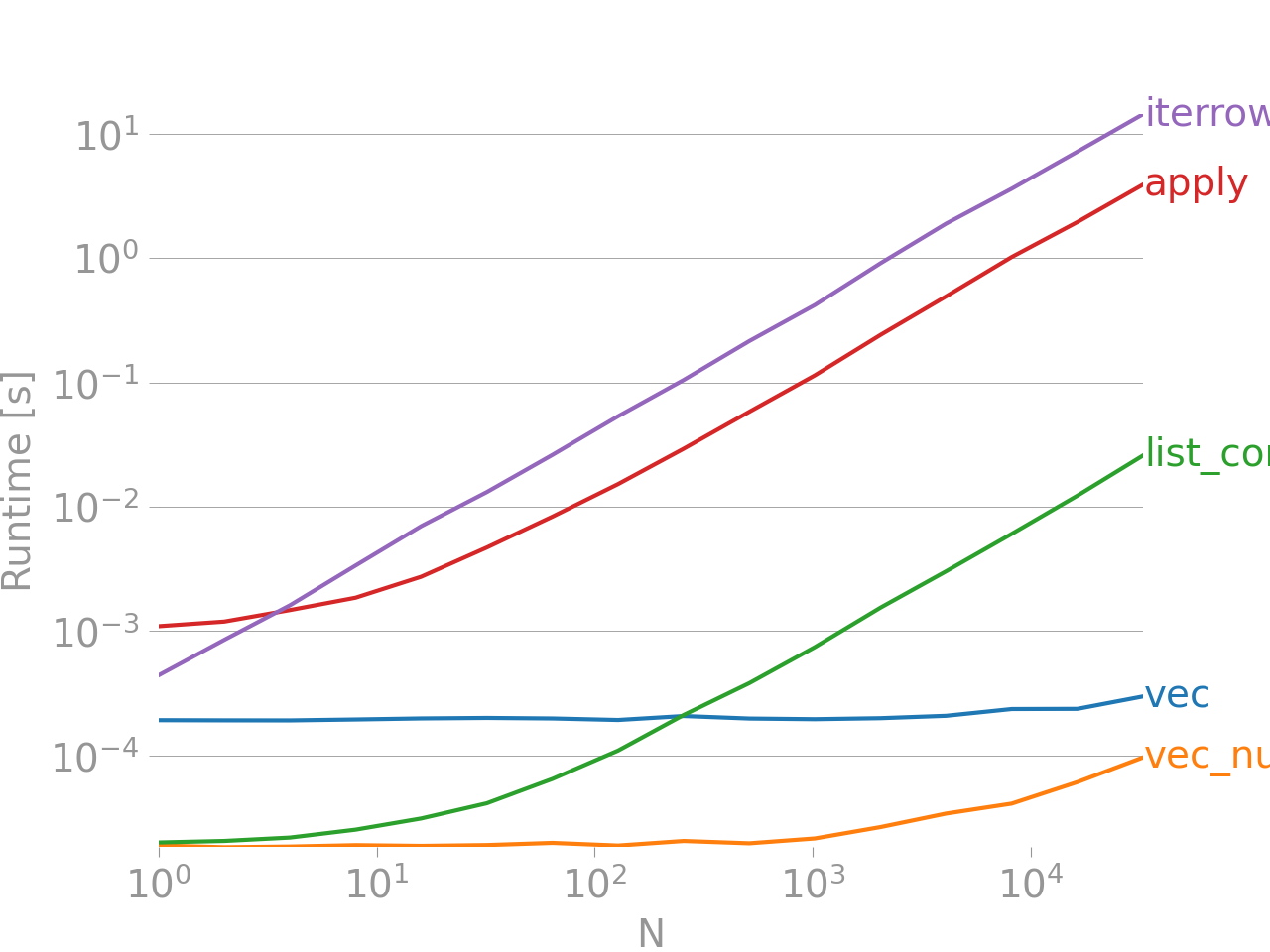
Here is the post’s benchmark of different methods that add two columns together.
As you can see, the vectorized implementation vec really outperforms
the other implementations at a large number of elements N.
I feel enlightened with this new understanding of Pandas.
I hope to gain some experience working with vectorized functions
and hopefully rewrite my old Energize Andover code to use them instead of
iterrows().